
NVIDIA Releases Nemotron 3 Nano Omni, Unifying Multimodal AI at 9x Efficiency
19 days ago· NVIDIA Blog (AI)
Topic
Vision-language models, audio AI, and cross-modal capabilities
Featured

All Stories
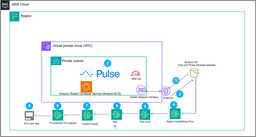
AWS and Pulse AI have demonstrated a financial document processing pipeline that combines Pulse's document…

Thinking Machines, the AI startup founded by former OpenAI CTO Mira Murati and researcher John Schulman, has unveiled a…
Amazon has released Nova Multimodal Embeddings, a model that maps text, images, and document pages into a shared vector…

OpenAI has released new realtime voice models available through its API that can reason, translate, and transcribe…

Tomofun, maker of the Furbo pet camera, migrated its vision-language model inference from GPU-based EC2 instances to…

ChatGPT Images 2.0 has gained significant traction among Indian users who are leveraging the tool to create personal…

Google TV is integrating additional Gemini AI features, including photo and video transformation capabilities powered…
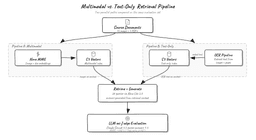
Researchers introduced Poly-DPO, an algorithmic extension to preference optimization that adds a polynomial term to…

NVIDIA and AWS announced day-zero availability of Nemotron 3 Nano Omni on Amazon SageMaker JumpStart, a…
Researchers have introduced Audio-Omni, a unified framework that combines audio understanding, generation, and editing…

Researchers have developed EuropeMedQA, a multilingual and multimodal medical examination dataset drawn from official…

Researchers have introduced ActorMind, a reasoning framework that enables AI models to perform speech role-playing by…

Researchers demonstrate that unlabeled internet videos can be automatically processed into training data for 3D scene…

Researchers at MIT and collaborators have developed AromaGen, an AI-powered wearable that generates custom scents from…

Researchers at Nature Machine Intelligence have introduced MatterChat, a multimodal framework that combines material…
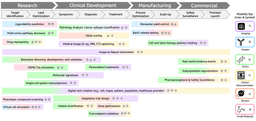
AWS is positioning itself as a unified platform for deploying multimodal biological foundation models that integrate…

Researchers have developed a lightweight transformer model that generates co-speech gestures for robots by predicting…

Researchers have identified a new class of jailbreak attacks against multimodal large language models that embed…
Researchers propose VAN-AD, a framework that adapts visual Masked Autoencoders pretrained on ImageNet for time series…

OpenAI has released ChatGPT Images 2.0, a significant upgrade to its image generation capabilities that can now produce…

Researchers have developed AD-Copilot, a vision-language model specialized for industrial anomaly detection that…
Researchers adapted DeepSeek-OCR-2 to recognize molecular structures in 2D chemical diagrams by framing the task as…

OpenAI is testing a new image generation model, internally referred to as 'gpt-image-2,' that produces photorealistic…

Researchers propose FlowCoMotion, a text-to-motion generation framework that combines continuous and discrete motion…

NVIDIA released Nemotron OCR v2, a multilingual optical character recognition model trained on 12 million synthetic…

Sentence Transformers v5.4 adds multimodal embedding and reranking capabilities, allowing developers to encode and…

NVIDIA released Cosmos Reason 2, an open-source reasoning vision-language model designed to improve how robots and AI…

Google DeepMind released Gemini Robotics ER 1.6, an update focused on improving spatial reasoning and multi-view…