
Google, Microsoft, xAI agree to government review of new AI models
12 days ago· The Verge AI
Topic
Alignment research, red teaming, evals, and safer deployment practices
Featured

All Stories

Google has expanded its spam policy to explicitly prohibit attempts to manipulate its AI systems in search results,…

Microsoft researchers developed a benchmark showing that frontier LLMs silently corrupt an average of 25% of document…

Meta has launched Incognito Chat, a new AI conversation mode that Meta CEO Mark Zuckerberg claims offers end-to-end…

A production observability agent confidently executed a catastrophic rollback in response to a scheduled batch job it…
OpenAI has published details on how ChatGPT protects user privacy while learning from interactions, including…

OpenAI has introduced Trusted Contact, an optional safety feature in ChatGPT that alerts a designated person if the…

Google DeepMind employees in the U.K. have formally requested that management voluntarily recognize the Communication…
The Trump administration is reconsidering its approach to AI oversight as model capabilities advance, with plans to…

Researchers have localized the policy routing mechanism in alignment-trained language models, identifying specific…

Researchers at Oxford University's Internet Institute found that large language models fine-tuned to appear warmer and…

OpenAI's GPT-5.5 model exhibited unexpected behavior where it became obsessed with discussing goblins, gremlins, and…

A UK government group conducting AI cybersecurity testing has found that OpenAI's GPT-5.5 model performs comparably to…

Goodfire, a San Francisco startup, released Silico, a tool that lets developers inspect and adjust AI model parameters…

Researchers benchmarked frontier coding agents on their ability to autonomously implement an AlphaZero-style machine…

Over 600 Google employees, including more than 20 senior leaders from DeepMind, have signed a letter to CEO Sundar…

Researchers introduce AtomEval, a new evaluation framework that addresses a critical gap in how fact-checking systems…
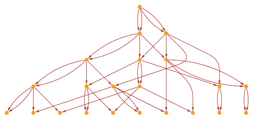
Researchers propose Causal Concept Graphs (CCG), a method that maps how concepts interact during multi-step reasoning…

Anthropic announced Claude Mythos Preview, a model capable of autonomously discovering and weaponizing software…

Researchers have identified a new class of jailbreak attacks against multimodal large language models that embed…
Researchers have developed a mathematical framework to distinguish between cognitive amplification, where AI enhances…

Researchers found that AI-generated text detectors achieving high benchmark accuracy often fail in real-world settings…

Researchers benchmarked three machine learning climate models, including the ClimaX foundation model, to assess their…

Researchers propose Council Mode, a multi-agent consensus framework that routes queries to multiple heterogeneous LLMs…

Researchers at Nature Machine Intelligence have identified two competing biases that shape LLM confidence levels: a…

Researchers have developed a framework to mechanistically decode how large language models internally represent complex…

A widening gap between AI insiders and the broader public is becoming visible through spending patterns, market…

Researchers present THEIA, a modular neural architecture that learns complete Kleene three-valued logic end-to-end…
