Finetuning Multimodal Models with Sentence Transformers
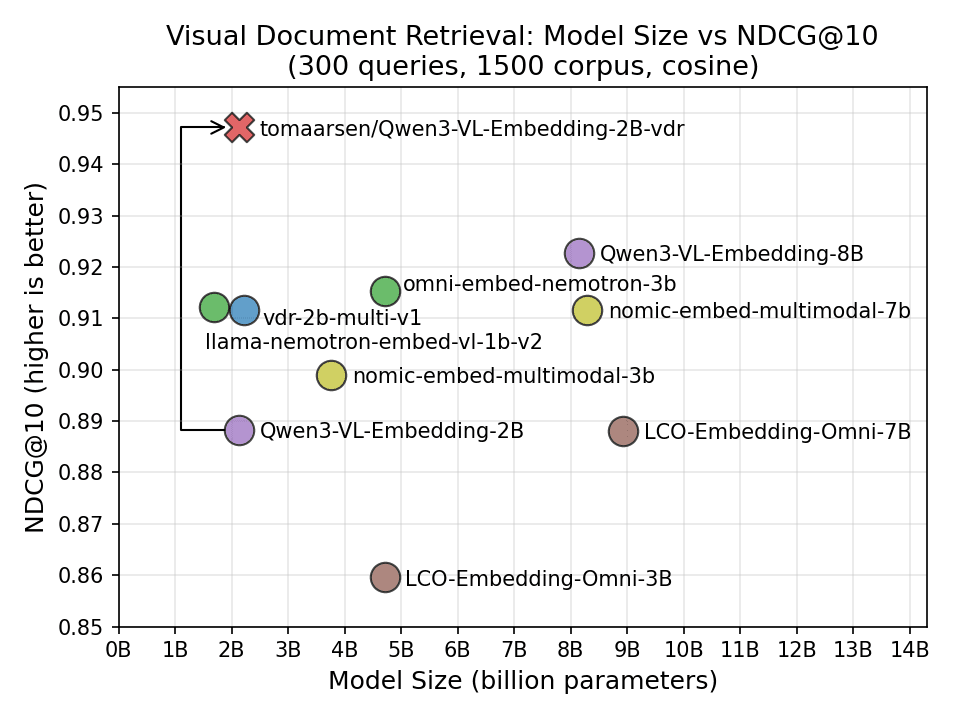
Sentence Transformers, a Python library for embedding and reranker models, now supports training and finetuning multimodal models that handle text, images, audio, and video. The post demonstrates finetuning Qwen/Qwen3-VL-Embedding-2B for Visual Document Retrieval, achieving an NDCG@10 of 0.947 versus the base model's 0.888, outperforming larger existing models. The training pipeline mirrors text-only approaches but handles multimodal data through the model's processor, with components including model selection, domain-specific datasets, loss functions, and evaluation tools.
TL;DR
- →Sentence Transformers now enables training multimodal embedding and reranker models on custom data for domain-specific tasks
- →Finetuning a 2B parameter vision-language model on Visual Document Retrieval improved performance from 0.888 to 0.947 NDCG@10, beating larger models
- →Training pipeline uses the same SentenceTransformerTrainer as text-only models, with automatic image preprocessing handled by the model's processor
- →Domain-specific finetuning addresses the limitation that general-purpose multimodal models rarely optimize for specialized tasks like document retrieval
Why it matters
Multimodal embedding models are increasingly central to retrieval-augmented generation and semantic search workflows, but off-the-shelf models often underperform on specialized tasks. This post demonstrates that modest-sized models can match or exceed much larger competitors when finetuned on domain data, lowering the barrier to building effective multimodal retrieval systems without massive compute budgets.
Business relevance
For teams building document retrieval, visual search, or multimodal RAG systems, finetuning enables competitive performance with smaller, cheaper models. A 2B parameter model achieving state-of-the-art results on Visual Document Retrieval reduces inference costs and deployment complexity compared to larger alternatives, making multimodal retrieval more accessible to resource-constrained organizations.
Key implications
- →Domain-specific finetuning is a practical path to competitive multimodal performance without scaling to larger models, reducing infrastructure and inference costs
- →The standardized training pipeline across text and multimodal models lowers the learning curve for teams already familiar with Sentence Transformers
- →Visual Document Retrieval performance gains suggest multimodal finetuning is particularly effective for document-heavy tasks involving layout, charts, and tables
What to watch
Monitor whether practitioners adopt this finetuning approach for other multimodal tasks beyond document retrieval, and track whether smaller finetuned models continue to outperform larger general-purpose alternatives in benchmarks. Also watch for community-contributed finetuned models and datasets that emerge on Hugging Face, which could accelerate adoption across different domains.
vff Briefing
Weekly signal. No noise. Built for founders, operators, and AI-curious professionals.
No spam. Unsubscribe any time.


